作者提出了一个用energy score检测OOD的统一框架,其既可以用于预训练网络分类器作为scoring fuction,也可以作为一个trainable cost function来微调分类模型。
Introduction
当机器学习模型看到与其训练数据不同的输入时,就会出现 out-of-distribution (OOD)uncertainty,因此模型很难对他们进行正确预测(也即在与训练数据分布差距较大的数据点上表现极差)。对于将 ML 应用于安全关键的应用(如罕见疾病鉴定)而言,确定输入是否超出了分布范围是一个基本问题。
OOD(Out-of-distribution)检测的传统方法之一是基于 softmax confidence。直觉上来看,对于 in distribution 的数据点,我们有高可信度给他们一个结果(就分类问题而言即将一张猫的图片分类为“猫”的概率很高),那么可信度低的就是 OOD inputs。但是因为 DNN 在样本空间的过拟合,经常会对OOD的样本(比如对抗样本)一个很高的可信度。
另一种检测方法是基于生成模型的,这类方法从生成建模的角度推导出似然分数log p(x) ,主要利用 Variational Autoencoder 的 reconstruction error 或者其他度量方式来判断一个样本是否属于 ID 或 OOD 样本。主要的假设是,Autoencoder 的隐含空间(latent space)能够学习出 ID 数据的明显特征 (silent vector),而对于 OOD 样本则不行,因此 OOD 样本会产生较高的 reconstruction error。这类方法的缺点在于生成模型难以优化而且不稳定,因为它需要对样本空间的归一化密度进行估计。
在本文中,作者使用 energy score 来检测 OOD 输入,ID 的数据 energy score 低,OOD 的数据 energy score 高。作者详尽证明了 energy score 优于基于 softmax 的得分和基于生成模型的方法。相比于基于 softmax 可信度得分的方法,energy score 不太受到 NN 在样本空间过拟合的影响。相比于基于生成模型的方法,energy score 又不需要进行显式的密度估计。
Background: Energy-based Models
基于能量的模型(EBM)的本质是构建一个函数 $E(x): \mathbb{R}^{D} \rightarrow \mathbb{R}$,它将输入空间中的每个点 $x$ 映射到一个称为能量的单个 non-probabilistic scalar。通过 Gibbs 分布我们可以将能量转化为概率密度:
$$
p(y \mid \mathbf{x})=\frac{e^{-E(\mathbf{x}, y) / T}}{\int_{y^{\prime}} e^{-E\left(\mathbf{x}, y^{\prime}\right) / T}}=\frac{e^{-E(\mathbf{x}, y) / T}}{e^{-E(\mathbf{x}) / T}}
$$
分母被称为配分函数,$T$ 是温度参数。此时我们可以得到任意点的自由能 $E(x)$ 为:
$$
E(\mathbf{x})=-T \cdot \log \int_{y^{\prime}} e^{-E\left(\mathbf{x}, y^{\prime}\right) / T}
$$
我们可以轻易的联系分类模型与能量模型,考虑一个 $K$ 类的 NN 分类器 $f(x): \mathbb{R}^{D} \rightarrow \mathbb{R}^{K}$ 将输入映射到 $K$ 个对数值,通过 softmax 归一化得到属于某一类别的概率,分类分布如下:
$$
p(y \mid \mathbf{x})=\frac{e^{f_{y}(\mathbf{x}) / T}}{\sum_{i}^{K} e^{f_{i}(\mathbf{x}) / T}}
$$
这里的 $f_{y}(x)$ 即 $f(x)$ 的第 $y$ 个值,而此时我们可以定义能量为 $E(x, y)=-f_{y}(x)$ 即负对数。同时我们可以得到关于 $x$ 的自由能:
$$
E(x, f)=-T \log \sum_{i=1}^{K} e^{f_{i}(x) / T}
$$
这里需要强调一下,这个能量已经与数据本身的标签无关了,可以看作是输出向量 $f(x)$ 的一种范数。
Energy-based Out-of-distribution Detection
Energy as Inference-time OOD Score
OOD是一个二分类问题,判别IND or OOD。自然想到可以利用数据的密度函数,认为低似然的例子为OOD。而利用基于能量的模型可以得到判别模型的密度函数:
$$
p(\mathbf{x})=\frac{e^{-E(\mathbf{x} ; f) / T}}{\int_{\mathbf{x}} e^{-E(\mathbf{x} ; f) / T}}
$$
其分母Z为配分函数,是未知的归一化函数,很难对输入空间进行计算,甚至难以进行可靠的估计。对上式两边取对数:
$$
\log p(\mathbf{x})=-E(\mathbf{x} ; f) / T-\underbrace{\log Z}_{\text {constant for all } \mathbf{x}}
$$
因为Z是样本独立的,不影响总体能量得分分布,所以-E(x;f)实际上与对数似然函数是线性对齐的,具有较高能量(较低可能性)的例子更可能为OOD数据。因此,可以使用能量函数E(x;f)进行OOD检测:
$$
G(\mathbf{x} ; \tau, f)=\left\{\begin{array}{ll}
0 & \text { if }-E(\mathbf{x} ; f) \leq \tau \\
1 & \text { if }-E(\mathbf{x} ; f)>\tau
\end{array}\right.
$$
在实际应用中,我们使用分布内的数据来选择阈值,从而使大量的输入被OOD检测器正确地分类。这里我们使用负能量得分-E(x;f),以符合正样本(IND)有更高的分数。能量分数本质上是非概率的,可以通过logsumexp运算符方便地计算出来。与JEM不同,我们的方法不需要明确估计密度Z,因为Z是样本独立的,不影响总体能量得分分布。
Energy Score vs. Softmax Score
作者从理论上证明softmax score无法对齐概率密度,对于任何预先训练过的神经网络,energy方法都可以作为softmax置信度简单而有效的替代,具体见原文。
Energy-bounded Learning for OOD Detection
虽然能量分数对于预先训练的神经网络是有用的,但分布内和分布外之间的能量差距可能并不总是最优的分化。因此,我们还提出了一个有能量边界的学习目标,通过将较低的能量分配给IND数据,将较高的能量分配给OOD数据,对神经网络进行微调,以明确创建一个能量差距。学习过程允许更大的灵活性来对比塑造能量表面,从而产生更多可区分的分布内和分布外数据。具体来说,我们的基于能量的分类器使用以下目标进行训练:
$$
\min _{\theta} \mathbb{E}_{(\mathbf{x}, y) \sim \mathcal{D}_{\text {in }}^{\text {train }}}\left[-\log F_{y}(\mathbf{x})\right]+\lambda \cdot L_{\text {energy }}
$$
整体 = 交叉熵损失+能量约束项,其中F(x)是softmax输出,$D_{in}^{train}$ 是IND训练数据。
$$
\begin{aligned}
L_{\text {energy }} &=\mathbb{E}_{\left(\mathbf{x}_{\text {in }}, y\right) \sim \mathcal{D}_{\text {in }}^{\text {train }}}\left(\max \left(0, E\left(\mathbf{x}_{\text {in }}\right)-m_{\text {in }}\right)\right)^{2} \\
&+\mathbb{E}_{\mathbf{x}_{\text {out }} \sim \mathcal{D}_{\text {out }}^{\text {train }}}\left(\max \left(0, m_{\text {out }}-E\left(\mathbf{x}_{\text {out }}\right)\right)\right)^{2}
\end{aligned}
$$
正则损失部分,用了两个平方的 hinge loss 来分别惩罚能量高于$m_{in}$的IND数据,和能量低于$m_{out}$的OOD数据。
Experiment
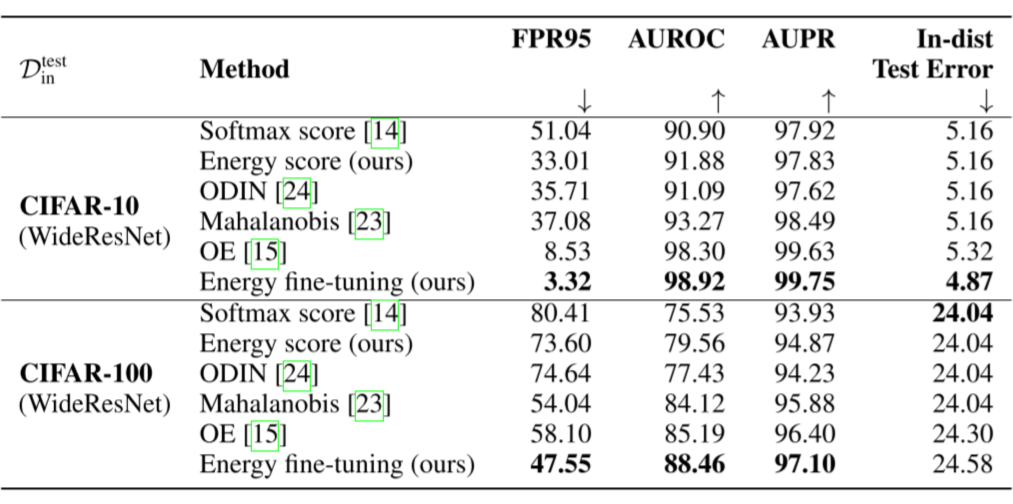
实验中有一点需要注意,作者采用了两个 setting:
No fine-tune: 使用 backbone 的输出,只是将 softmax confidence 换成能量得分。注意样本的能量我们定义为 $E(x, f)=-T \log \sum_{i=1}^{K} e^{f_{i}(x) / T}$,其中 $f_{i}(x)$ 即 backbone 的第 $i$ 维输出。
Fine-tune:使用上述的损失函数对 backbone 进行 fine-tune,然后使用 energy score 进行 OOD 检测。
实验统一使用 WideResNet 作为预训练分类模型,在六种 OOD 数据集上的表现如下,可以看到在不进行 fine-tune 的情况下基本碾压了基于 softmax confidence 的方法。有 fine-tune 的情况下,也比目前的 sota-OE 好很多。