主要介绍可控语言模型生成,分为三类:decoding strategy, smart prompt design, finetune
Introduction
最新的语言模型(LM)已在不受监督的Web数据的情况下进行了大规模预训练。 通过迭代采样下一个标记从LM生成样本时,我们对输出文本的属性(如主题,样式,情感等)没有太多控制。许多应用程序都需要对模型输出进行良好的控制。 例如,如果我们计划使用LM来为孩子们生成阅读材料,那么我们希望指导输出的故事是安全的,有教育意义的,并且易于孩子理解。
如何引导强大的无条件语言模型? 在本文中,我们将深入研究几种使用无条件语言模型生成受控内容的方法。 注意,模型的可操纵性仍然是一个开放的研究问题。 每种引入的方法都有其优点和缺点。
- Apply guided decoding strategies and select desired outputs at test time.
- Optimize for the most desired outcomes via good prompt design.
- Finetune the base model or steerable layers to do conditioned content generation.
Decoding Strategies
Common Decoding Methods
此类方法是对原始的生成概率做一些调整,不涉及到模型参数的更新。原始的生成概率计算为:
$$p_{i} \propto \frac{\exp \left(o_{i} / T\right)}{\sum_{j} \exp \left(o_{j} / T\right)}$$
- Greedy search:始终选择最高概率的下一个token,相当于设置温度T = 0。 但是,即使对于训练有素的模型,它也会倾向于生成重复的词。
- Beam search:维护一个容量为k的候选集合,保存前top k个候选句。这种方法也存在问题,如下所示:
)](https://lilianweng.github.io/lil-log/assets/images/beam_search_less_surprising.png)
- Top-k sampling:Fan et al., 2018提出了一种先选择top k个候选句,然后从中随机选择下一个token。论文认为与beam search相比,这种方法可以产生更新颖、更少重复的内容。Nucleus sampling类似。
- Penalized sampling:为了避免产生重复子字符串,CTRL提出了一种新的采样方法,通过降低对先前生成的token的分数来惩罚重复,下一个令牌的概率分布定义为:
$$
p_{i}=\frac{\exp \left(o_{i} /(T \cdot \mathbb{1}(i \in g))\right)}{\sum_{j} \exp \left(o_{j} /(T \cdot \mathbb{1}(j \in g))\right)} \quad \mathbb{1}(c)=\theta \text { if the condition } c \text { is True else } 1
$$
$g$是之前已生成token的集合,$\mathbb{l}$是identity function,$\theta=1.2$来保证在减少重复和真实生成之间取得良好的平衡。
Guided Decoding && Trainable Decoding
Smart Prompt Design
大型语言模型已经被证明在许多NLP任务中非常强大,即使只有提示而没有特定任务的微调(GPT2, GPT3)。提示设计对下游任务的性能有很大的影响,通常需要耗时的手工制作。例如,在闭卷考试中,事实性问题可以通过智能提示设计得到很大的提升Shin et al., 2020, Jiang et al., 2020)。
Gradient-based Search
AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
- 2020.11
- AutoPrompt根据模板$\lambda$,将原始任务输入$x$与一系列触发令牌$x_{trig}$相结合,构建一个提示符。注意触发器令牌在所有输入中共享,因此普遍有效。
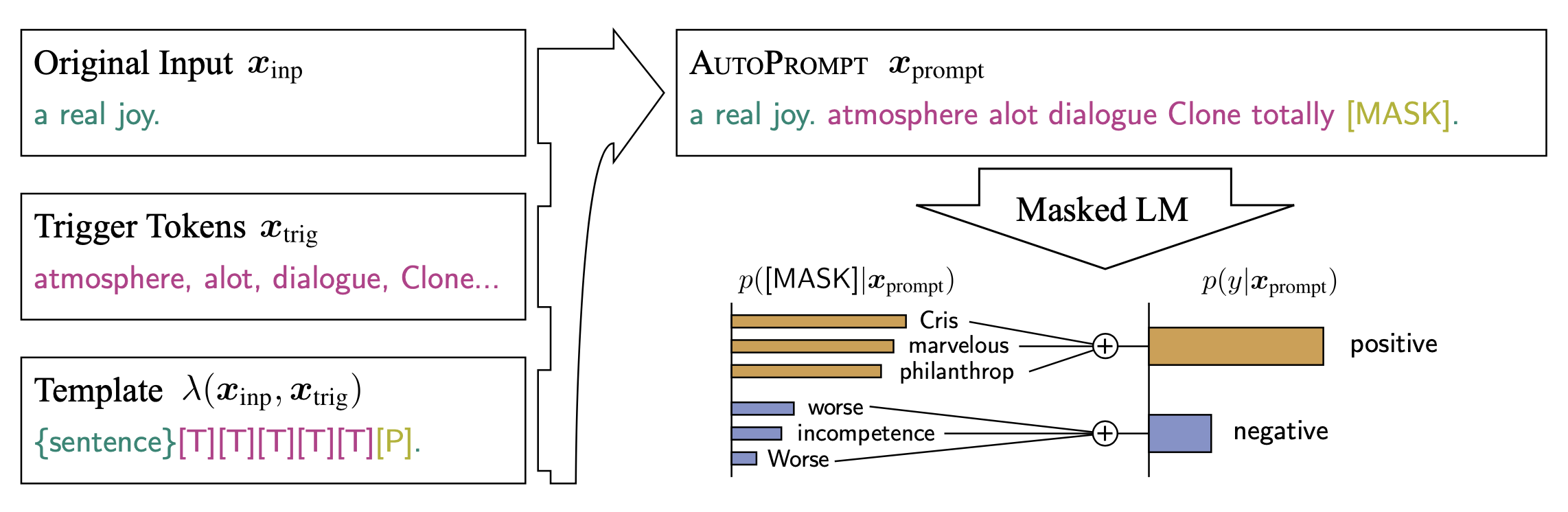
- AutoPrompt使用梯度搜索机制来寻找触发词$x_{trig}$,本质上是计算监督损失的一阶导数:$$
e_{\mathrm{trig}}^{(t+1)}=\arg \min _{e \in \mathcal{V}}\left[e-e_{\mathrm{trig}}^{(t)}\right]^{\top} \nabla_{e_{\mathrm{trig}}^{(t)}} \mathcal{L}
$$
类似于计算扰动然后找knn近邻。示意图如下: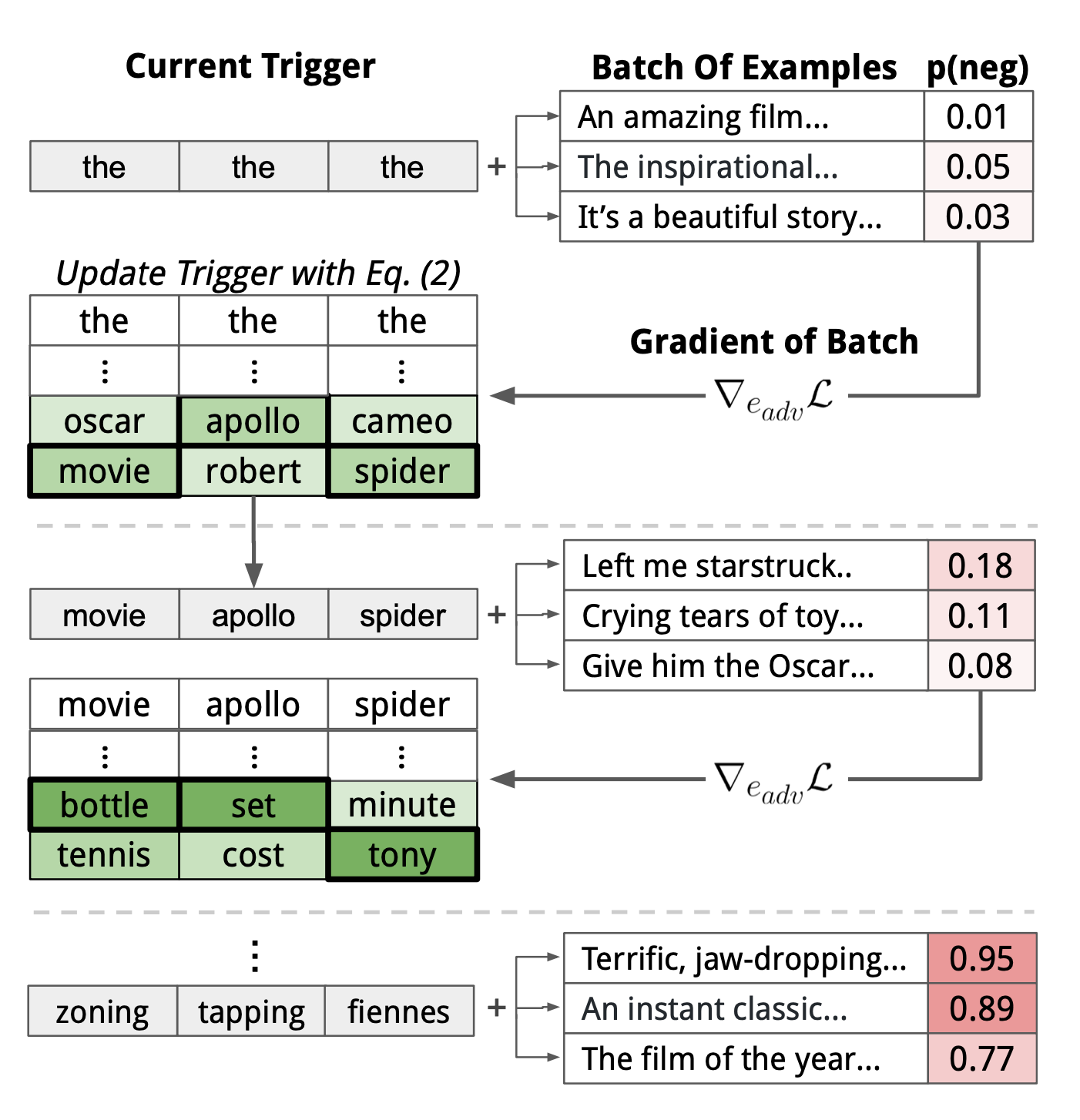
- 生成prompt之后,通过[MASK]来预测下游任务。这里作者做了一些简化:对于由词表中的词生成的标签,直接通过[MASK]预测;而对于类似positive/negative这种二分类任务,作者首先通过一个二分类模型预测每个类别对应的类别词,然后对类别下所有类别词的生成概率进行求和,作为最终的预测概率。$$
p\left(y \mid \boldsymbol{x}_{\text {prompt }}\right)=\sum_{w \in \mathcal{V}_{y}} p\left([\mathrm{MASK}]=w \mid \boldsymbol{x}_{\text {prompt }}\right)
$$ - 实验结果:

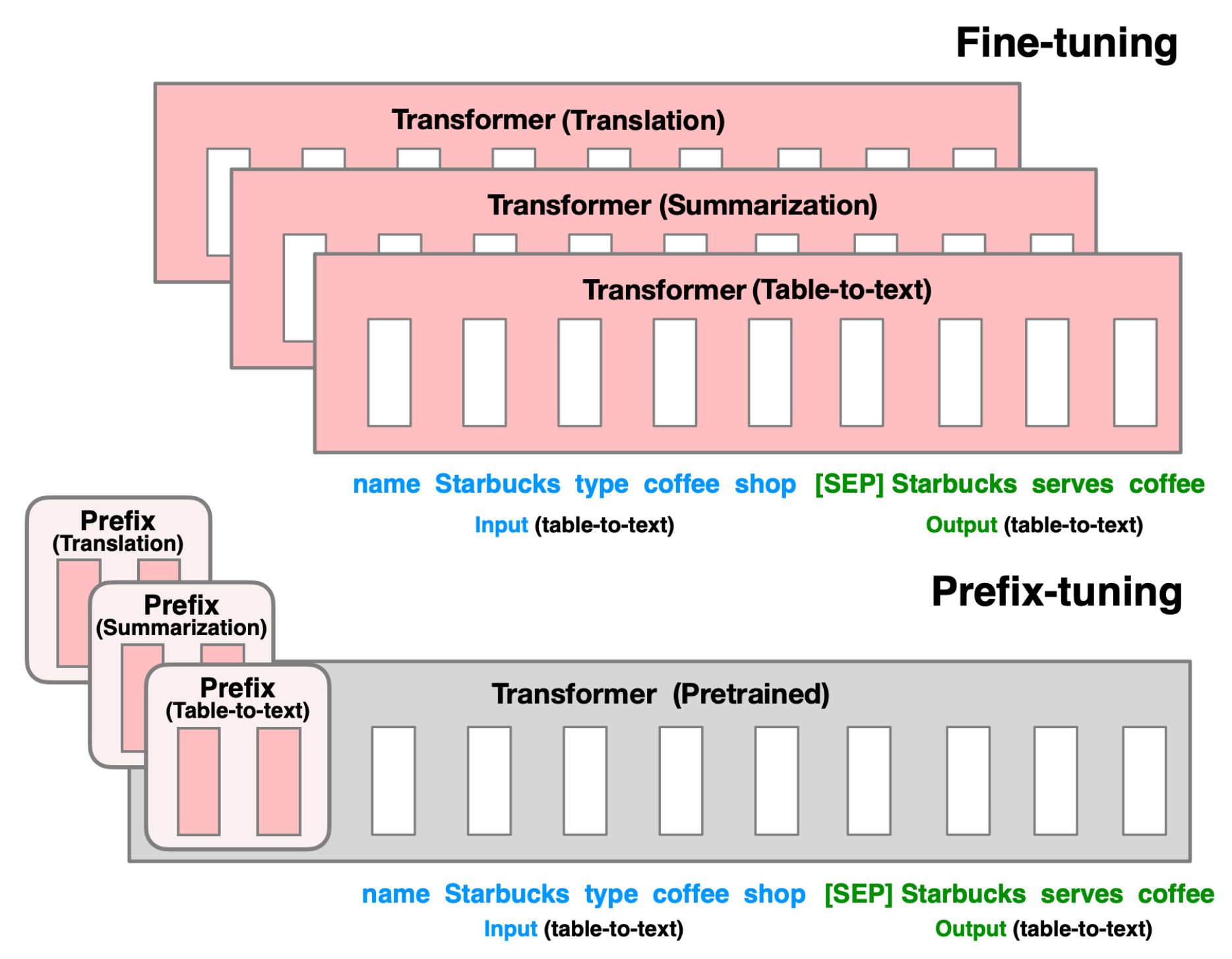
Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 2021.1
Smart prompt design essentially produces efficient context that can lead to desired completion.
- Prefix-Tuning指在输入序列(命名为prefix)的开头指定少量可训练的参数来控制LM, [prefix;x;y]。Let $P_{idx}$ be a set of prefix indices and dim($h_{i}$) be the embedding size. The prefix parameters $P_{\theta}$ has the dimension $|P_{idx}| \times dim(h_{i})$ and the hidden state takes the form:$$
h_{i}=\left\{\begin{array}{ll}
P_{\theta}[i,:], & \text { if } i \in \mathcal{P}_{\text {idx }} \\
\operatorname{LM}_{\phi}\left(z_{i}, h_{<i}\right), & \text { otherwise }
\end{array}\right.
$$ - 注意训练时预训练模型的参数固定:
- 实验结果:
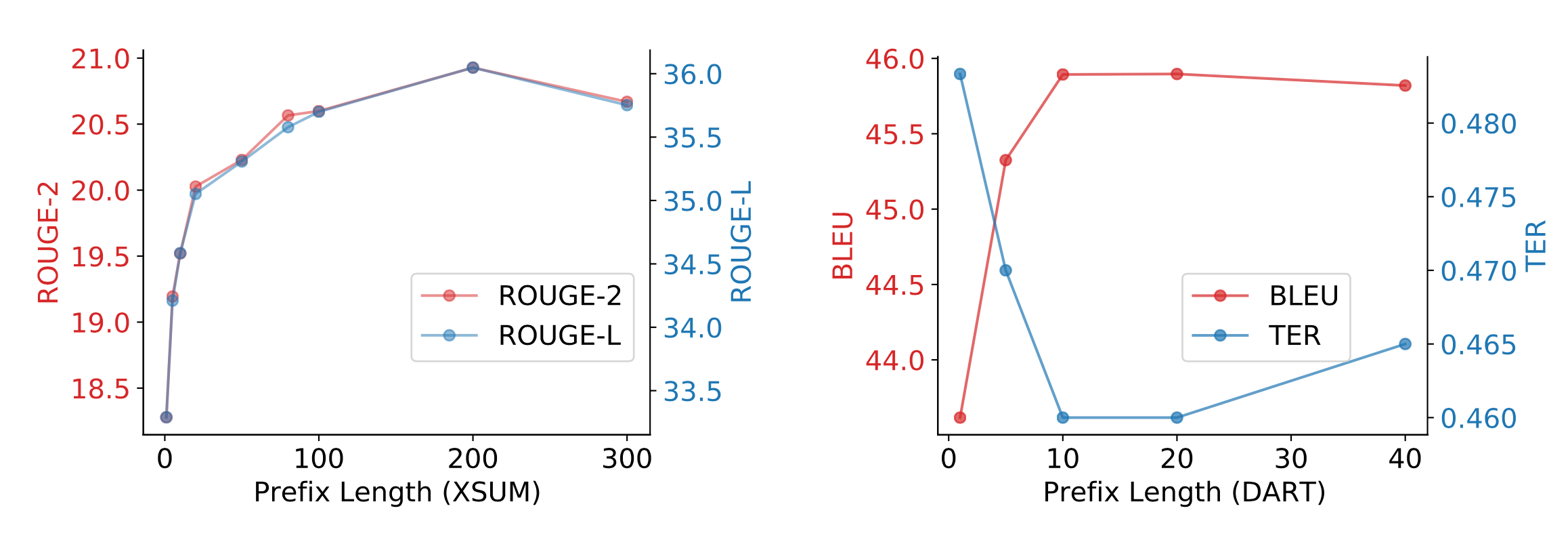
- 结论:
Fine-tuned models achieve better task performance but they can fail in the low data regime. Both AutoPrompt and Prefix-Tuning were found to outperform fine-tuning in the regime where the training dataset is small (i.e. 10^2 − 10^3 samples). As an alternative to fine-tuning, prompt design or learning the context embedding is much cheaper. AutoPrompt improves the accuracy for sentiment classification a lot more than manual prompts and achieves similar performance as linear probing. For the NLI task, AutoPrompt obtains higher accuracy than linear probing. It is able to retrieve facts more accurately than manual prompts too. In low data regime, Prefix-Tuning achieves performance comparable with fine-tuning on table-to-text generation and summarization.
Heuristic-based Search
Finetuning
_refer to https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html#fine-tuning_