本文研究在BERT预训练模型的基础上增加外部KB知识,实验证明在MRC任务上取得了优于BERT的表现。
paper: https://drive.google.com/open?id=156rShpAzTax0Pzql1yuHVuT-tg6Qf_xX
source: ACL 2019
code: http://github.com/paddlepaddle/models/tree/develop/PaddleNLP/Research/ACL2019-KTNET
Introduction
本文的出发点是BERT预训练模型通过语言模型只能获取语言知识(linguistic regularities),而在MRC任务中,也需要外部KB提供背景知识,如下所示:
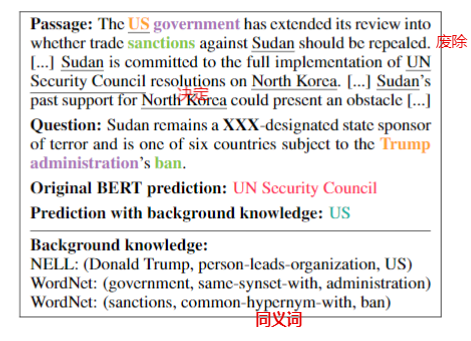
本文使用的外部KB包括WordNet(records lexical relations between words)和NELL(stores beliefs about entities),在融合KB知识的过程并没有使用符号事实(symbolic facts)的方法,而是使用分布式Embedding的方法。这样做有两个优势:(1)融合的KB知识不仅与阅读文本局部相关,而且也包含KB的整体知识;(2)能够同时融入多个KB知识源,而不需要task-specific engineering。
Approach
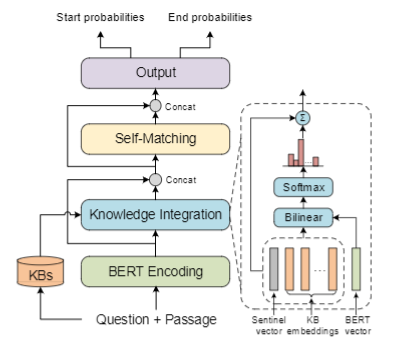
KT-NET主要有四个模块:BERT encoding layer负责获取问题和段落的上下文表示;knowledge integration layer
使用注意力机制选择最相关的KB编码,然后与BERT表示融合;self-matching layer构建BERT与KB编码之间的交互;output layer预测最终的答案。整体结构如下所示:
本文解决的任务是机器阅读理解(MRC),给定段落 $P= \{p_{i}\}^{m}_{i=1}$ 和问题 $Q= \{q_{j}\}^{n}_{j=1}$,我们的目的是预测答案$A= \{p_{i}\}^{b}_{i=a}$,限定答案只能从段落中取一个片段,实际转化为预测两个边界。
Knowledge Embedding and Retrieval
给定段落P和问题Q,模型使用所有的词 $w \in P \cup Q$ 做检索,得到潜在相关的KB concept集合$C(w)$,其中每一个concept $c \in C(w)$ 都会对应一个向量表示 $\textbf{c}$。具体来说,作者使用了两个KB:WordNet和NELL。二者都以 (subject, relation, object) 的格式存储,每一个三元组都代表了两个实体之间的特定关系。WordNet存储的是同义词(word synsets)之间的词级别关联,而NELL存储的是 beliefs between entities,其中subject一般是真实世界中的实体,而object可以是实体:_(Coca Cola, headquartered in, Atlanta)_,也可以是concept:_(Coca Cola, is_a, company)_,在本文里则不区分之间的差别,统一称之为实体(entity)。
作者使用BILINEAR模型来获取实体和关系表征。在本文中,所有的WordNet synsets和NELL concepts都是从KB中检索得到的,类似于 Leveraging knowledge bases in lstms for improving machine reading。对于WordNet,给定段落或者问题中的一个词,模型返回其所有的同义词作为candidate KB concepts;对于NELL,首先进行NER,然后使用字符串匹配的方法用识别出的命名实体去检索出相关的NELL concepts做候选集。注意同一个命名实体中的所有词以及同一个词中的所有子词共享同一个concept,例如对于_Coca_和_Cola_都对应同一个concept: _Company_,而每一个concept都会对应一个向量表征。作者认为这样做的好处在于可以兼顾局部信息以及KB全局信息,并且方便同时融合多个KB。
BERT Encoding Layer 首先将段落P和问题Q拼接成 $S=[\langle\mathrm{CLS}\rangle, Q,\langle\mathrm{SEP}\rangle, P,\langle\mathrm{SEP}\rangle]$,对S中的每一个token,使用 token, position, segment 编码 $\mathbf{h}_{i}^{0}=\mathbf{s}_{i}^{\mathrm{tok}}+\mathbf{s}_{i}^{\mathrm{pos}}+\mathbf{s}_{i}^{\mathrm{seg}}$,Q中的所有词认为是同一个segment,共享相同的segment embedding,而P中的所有词则共享另一个segment embedding,然后通过Transformer encoders,最终得到 $\left\{\mathbf{h}_{i}^{L}\right\}_{i=1}^{m+n+3} \in \mathbb{R}^{d_{1}}$。
Knowledge Integration Layer 这个模块负责将上下文信息与KB知识相融合,是整个模型的核心。本质上利用BERT表示$\mathbf{h}_{i}^{L} \in \mathbb{R}^{d_{1}}$对KB concepts候选集$C(s_{i})$做注意力,来选取最相关的KB concepts。作者使用 $\alpha_{i j} \propto \exp \left(\mathbf{c}_{j}^{\top} \mathbf{W h}_{i}^{L}\right)$ 计算注意力权重。因为KB concepts不一定与token密切相关,作者采取了类似Leveraging knowledge bases in lstms for improving machine reading的方法,引入了一个 knowledge sentinel $\overline{\mathbf{c}} \in \mathbb{R}^{d_{2}}$,同样计算相似度:$\beta_{i} \propto \exp \left(\mathbf{\overline{c}}^{\top} \mathbf{W} \mathbf{h}_{i}^{L}\right)$,然后:
$$
\mathbf{k}_{i}=\sum_{j} \alpha_{i j} \mathbf{c}_{j}+\beta_{i} \overline{\mathbf{c}}
$$
其中$\sum_{j} \alpha_{i j}+\beta_{i}=1$,如果token $s_{i}$对应的concepts集合为空,则$\mathbf{k}_{i}=0$。然后输出 $\textbf{u}_{i}=[\mathbf{h}_{i}^{L}, \mathbf{k}_{i}] \in \mathbb{R}^{d_{1}+d_{2}}$,因此同时捕获context-aware和knowledge-aware的知识。
Self-Matching Layer 本质上是一个自注意力层,目的是构建context embedding $\mathbf{h}_{i}^{L}$ 与 knowledge embedding $\mathbf{k}_{i}$ 之间的交互。作者构建了两层交互:direct 和 indirect。首先通过 $r_{i j}=\mathbf{w}^{\top}\left[\mathbf{u}_{i}, \mathbf{u}_{j}, \mathbf{u}_{i} \odot \mathbf{u}_{j}\right]$ 得到相似度矩阵$\textbf{R}$ 以及按行softmax归一化后的权重矩阵$\textbf{A}$。直接交互是指$\mathbf{v}_{i}=\sum_{j} a_{i j} \mathbf{u}_{j}$,而间接交互是指:
$$
\begin{aligned} \mathbf{\overline{A}} &=\mathbf{A}^{2} \\ \overline{\mathbf{v}}_{i} &=\sum_{j} \bar{a}_{i j} \mathbf{u}_{j} \end{aligned}
$$
最终得到输出$\textbf{o}_{i}=\left[\mathbf{u}_{i}, \mathbf{v}_{i}, \mathbf{u}_{i}-\mathbf{v}_{i}, \mathbf{u}_{i} \odot \mathbf{v}_{i}, \mathbf{\overline{v}}_{i}, \mathbf{u}_{i}-\overline{\mathbf{v}}_{i}\right] \in \mathbb{R}^{6 d_{1}+6 d_{2}}$。
Output Layer 输出层与原始的NERT保持一致,只是简单的线性层,分别预测左右边界。
$$
p_{i}^{1}=\frac{\exp \left(\mathbf{w}_{1}^{\top} \mathbf{o}_{i}\right)}{\sum_{j} \exp \left(\mathbf{w}_{1}^{\top} \mathbf{o}_{j}\right)}, \quad p_{i}^{2}=\frac{\exp \left(\mathbf{w}_{2}^{\top} \mathbf{o}_{i}\right)}{\sum_{j} \exp \left(\mathbf{w}_{2}^{\top} \mathbf{o}_{j}\right)}
$$
损失函数为极大似然:$\mathcal{L}=-\frac{1}{N} \sum_{j=1}^{N}\left(\log p_{y_{j}^{1}}^{1}+\log p_{y_{j}^{2}}^{2}\right)$。
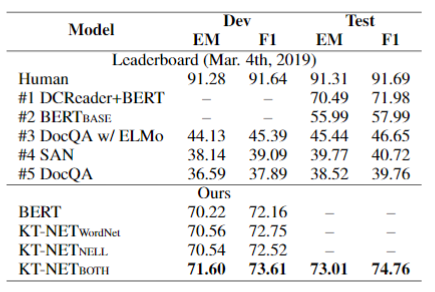
Experiments

Conclusion
本文提出了KT-NET模型,使用外部KB知识增强BERT,论文使用了WordNet和NELL两个KB,在MRC任务取得了不错的表现。